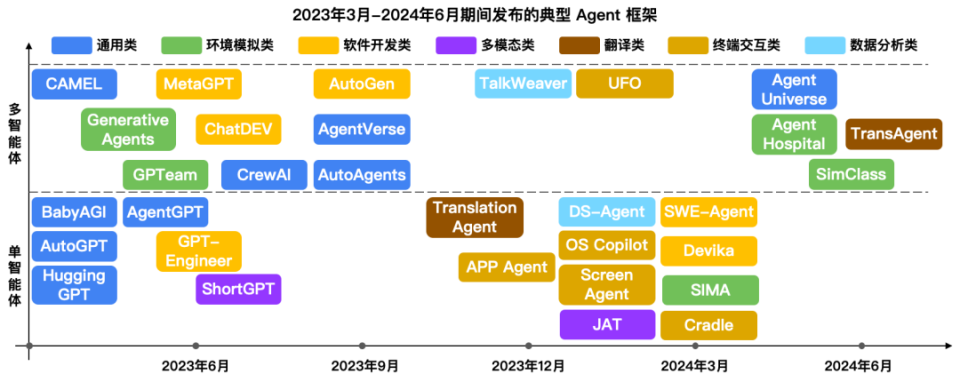
国内软件科技领域迎来了一波AI Agent产品的发布热潮,短短时间内已有近50款相关产品问世,覆盖了智能客服、办公助手、行业顾问、个性化推荐等多个场景。这一现象既彰显了市场对人工智能技术落地的热情,也引发了一个核心的追问:当前的技术发展水平,是否足以支撑这些产品在实际应用中的可靠性与稳定性?
从技术开发的视角审视,AI Agent的可靠性建立在几个关键的技术支柱之上。首先是核心的模型能力。得益于大语言模型(LLM)技术的快速发展,特别是中文理解与生成能力的显著提升,国产基础模型在语义理解、逻辑推理、任务规划等方面取得了长足进步。这为Agent提供了“大脑”,使其能够更准确地理解用户意图、分解复杂任务。模型固有的“幻觉”问题(即生成看似合理但不准确或虚假的信息)、对长上下文处理的稳定性、以及特定领域知识的深度和时效性,仍然是影响Agent输出可靠性的主要技术挑战。许多产品在简单、封闭场景下表现良好,但在开放、动态或高专业要求的真实业务环境中,其表现可能出现波动。
其次是智能体(Agent)框架与工程化能力。一个可靠的AI Agent不仅仅是调用大模型API,更是一个集成了规划、记忆、工具调用、多轮对话管理、安全与合规校验等模块的复杂系统。国内开发者在基于国外开源框架(如LangChain、AutoGPT)进行快速迭代和本土化创新的也在自主研发更适应中文环境和国内业务逻辑的Agent框架。工程化的关键在于如何将这些模块稳健地集成,确保系统在高并发下的响应速度、在多步骤任务执行中的错误恢复能力、以及在与外部工具、数据库、API交互时的稳定与安全。目前,许多产品仍处于快速原型验证或小范围试用阶段,其架构在面对大规模、高复杂度的真实生产环境压力时,其鲁棒性和可维护性仍需经过更长时间的考验。
再者是数据与反馈闭环。AI Agent的持续优化和可靠性提升,高度依赖于高质量的训练数据、精调(Fine-tuning)以及基于真实用户交互的强化学习(RLHF/RLAIF)。国内企业虽然在数据积累方面有场景优势,但如何构建高效、合规的数据管道,清洗和标注高质量的对齐数据,并设计有效的在线学习与迭代机制,是技术落地的深水区。缺乏持续、优质反馈闭环的产品,其性能可能停滞不前,甚至随着业务变化而退化。
最后是生态与标准初现。众多产品的涌现也催生了对中间件、评估基准、测试工具和行业标准的需求。目前,针对AI Agent的可靠性、安全性、性能的评估体系尚不完善,缺乏公认的、贴合中国应用场景的测试标准。这导致用户难以横向比较不同产品的真实可靠度,也增加了企业选型和集成的风险。
国内AI Agent产品的密集问世,反映了技术探索和市场需求的双轮驱动。当前的技术基础——特别是在大模型能力、基础框架搭建上——已经为应用提供了可行的起点,使得在诸多垂直和轻度场景中部署相对可靠的Agent成为可能。要支撑起在关键业务、复杂流程和高可靠性要求场景下的规模化、高可信应用,技术层面仍面临诸多挑战:需要进一步攻克核心模型的可靠性短板,提升Agent系统工程化的成熟度,构建可持续进化的数据与训练闭环,并逐步建立完善的评估与标准体系。
因此,对于“技术是否足够支撑应用可靠性”这一问题,答案或许是“初步支撑,但远未成熟”。当前阶段是产品百花齐放、场景快速验证的“上半场”,而决定胜负的“下半场”将取决于各厂商如何深耕技术细节,夯实工程基础,在真实的商业闭环中持续打磨产品的稳定性和价值深度,从而将技术潜力转化为坚实可靠的生产力。